Versiones no soportadas:2.6 2.5 2.4 2.3 2.2 2.1 2.0
Conceptos de pgRouting¶
Esta es una guía simple que va a través de los pasos básicos para empezar trabajar con pgRouting. Esta guía cubre:
Grafos¶
Definición de grafo¶
Un grafo es un par ordenado
Hay diferentes tipos de grafos:
Grafo no dirigido
Grafo no dirigido simple
Grafo dirigido
Grafo dirigido simple
Grafos:
No tienen geometrías.
Algunos problemas de teoría de grafos requieren tener pesos, llamados cost en pgRouting.
En pgRouting hay varias maneras de representar in grafo en la base de datos:
Con
cost(
id,source,target,cost)
Con
costyreverse_cost(
id,source,target,cost,reverse_cost)
Donde:
Columna |
Descripción |
|---|---|
|
Identificador de la asirsta. Requerimiento para mantener consistente la base de datos. |
|
Identificador de un vértice. |
|
Identificador de un vértice. |
|
Peso de la arista (
|
|
Peso de la arista (
|
La decisión del grafo de ser directed o undirected es resultado al ejecutar el algoritmo de pgRouting.
Grafo con cost¶
El grafo ponderado dirigido,
Datos de l grafo se obtienen mediante una consulta
SELECT id, source, target, cost FROM edgesEl conjunto de aristas
Aristas donde
costes no negativo son parte del grafo.
el conjunto de vértices
Todos los vértices``source`` y
targetson parte del grafo.
Grafo dirigido
En un grafo dirigido la arista
Para los siguientes datos:
SELECT *
FROM (VALUES (1, 1, 2, 5), (2, 1, 3, -3))
AS t(id, source, target, cost);
id | source | target | cost
----+--------+--------+------
1 | 1 | 2 | 5
2 | 1 | 3 | -3
(2 rows)
La arista
Los datos se representan en el siguiente grafo:
![digraph G {
1 -> 2 [label="1(5)"];
3;
}](_images/graphviz-6bd797ca50768e0f10212a0236a85afbd8bb3771.png)
Grafo no dirigido
En un grafo no dirigido la arista
En términos de un grafo dirigido es como tener dos aristas:
Para los siguientes datos:
SELECT *
FROM (VALUES (1, 1, 2, 5), (2, 1, 3, -3))
AS t(id, source, target, cost);
id | source | target | cost
----+--------+--------+------
1 | 1 | 2 | 5
2 | 1 | 3 | -3
(2 rows)
Arista
Los datos se representan en el siguiente grafo:
![graph G {
1 -- 2 [label="1(5)"];
3;
}](_images/graphviz-18dbb5ac9f77e565b643a0f0e7310253dedbee20.png)
Grafo con cost y reverse_cost¶
El ponderado del grafo dirigido,
Datos de l grafo se obtienen mediante una consulta
SELECT id, source, target, cost, reverse_cost FROM edgesEl conjunto de aristas
Aristas
costes no negativo son parte del grafo.Aristas
reverse_costes no negativo son parte del grafo.
El conjunto de vértices
Todos los vértices``source`` y
targetson parte del grafo.
Grafo dirigido
En un grafo dirigido ambas aristas tiene direccionalidad
arista
arista
Para los siguientes datos:
SELECT *
FROM (VALUES (1, 1, 2, 5, 2), (2, 1, 3, -3, 4), (3, 2, 3, 7, -1))
AS t(id, source, target, cost, reverse_cost);
id | source | target | cost | reverse_cost
----+--------+--------+------+--------------
1 | 1 | 2 | 5 | 2
2 | 1 | 3 | -3 | 4
3 | 2 | 3 | 7 | -1
(3 rows)
Aristas no son parte del grafo:
Los datos se representan en el siguiente grafo:
![digraph G {
1 -> 2 [label="1(5)"];
2 -> 1 [label="1(2)"];
3 -> 1 [label="2(4)"];
2 -> 3 [label="3(7)"];
}](_images/graphviz-c2169ba4585bf5915ed2425fe4db5e9152ef0227.png)
Grafo no dirigido
En un grafo dirigido ambas aristas no tiene direccionalidad
Arista
Arista
En términos de un grafo dirigido es como tener cuatro aristas:
Para los siguientes datos:
SELECT *
FROM (VALUES (1, 1, 2, 5, 2), (2, 1, 3, -3, 4), (3, 2, 3, 7, -1))
AS t(id, source, target, cost, reverse_cost);
id | source | target | cost | reverse_cost
----+--------+--------+------+--------------
1 | 1 | 2 | 5 | 2
2 | 1 | 3 | -3 | 4
3 | 2 | 3 | 7 | -1
(3 rows)
Aristas no son parte del grafo:
Los datos se representan en el siguiente grafo:
![graph G {
1 -- 2 [label="1(5)"];
2 -- 1 [label="1(2)"];
3 -- 1 [label="2(4)"];
2 -- 3 [label="3(7)"];
}](_images/graphviz-50eb78779f612b19ac347e75cdae53525e6a5576.png)
Grafos sin geometrías¶
Relaciones personales, genealogía, problemas de dependencia de archivos puede ser resueltos usando pgRouting. Esos problemas, normalmente, no vienen con las geometrías asociadas con el grafo.
Ejemplo de Wiki¶
Resuelva el problema de ejemplo tomado de wikipedia):
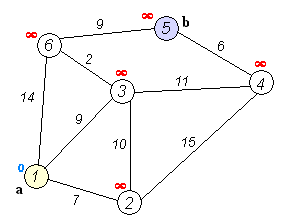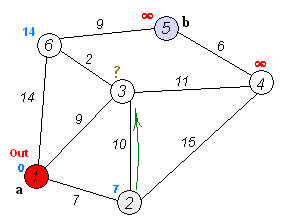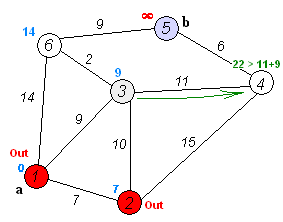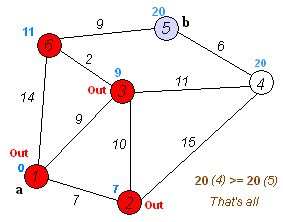
Donde:
Problema es encontrar el camino mas corto desde
Es un grafo dirigido.
Aunque visualmente se vea con geometrías, el dibujo no es a escala.
Las geometrías no esta asociadas con los vértices o aristas
Tiene 6 vértices
Tiene 9 aristas:
El grafo puede ser representados de varias maneras por ejemplo:
![graph G {
rankdir="LR";
1 [color="red"];
5 [color="green"];
1 -- 2 [label="(7)"];
5 -- 6 [label="(9)"];
1 -- 3 [label="(9)"];
1 -- 6 [label="(14)"];
2 -- 3 [label="(10)"];
2 -- 4 [label="(13)"];
3 -- 4 [label="(11)"];
3 -- 6 [label="(2)"];
4 -- 5 [label="(6)"];
}](_images/graphviz-e1e7271c22c7d8991843607dc481d11949ba6f18.png)
Prepara la base de datos¶
Crea una base de datos para el ejemplo, acceda a la base de datos e instala pgRouting:
$ createdb wiki
$ psql wiki
wiki =# CREATE EXTENSION pgRouting CASCADE;
Crear una tabla¶
Los elementos básicos necesarios para realizar routing básico en un grafo no dirigido son:
Columna |
Tipo |
Descripción |
|---|---|---|
|
ENTEROS |
Identificador de la arista. |
|
ENTEROS |
Identificador del primer vértice de la arista. |
|
ENTEROS |
Identificador del segundo vértice de la arista. |
|
FLOTANTES |
Peso de la arista ( |
Donde:
- ENTEROS:
SMALLINT, INTEGER, BIGINT- FLOTANTES:
SMALLINT, INTEGER, BIGINT, REAL, FLOAT
Usando este diseño de tabla para este ejemplo:
CREATE TABLE wiki (
id SERIAL,
source INTEGER,
target INTEGER,
cost INTEGER);
CREATE TABLE
Introduzca los datos¶
INSERT INTO wiki (source, target, cost) VALUES
(1, 2, 7), (1, 3, 9), (1, 6, 14),
(2, 3, 10), (2, 4, 15),
(3, 6, 2), (3, 4, 11),
(4, 5, 6),
(5, 6, 9);
INSERT 0 9
En cuentre el camino más corto¶
Para resolver el ejemplo se usa pgr_dijkstra:
SELECT * FROM pgr_dijkstra(
'SELECT id, source, target, cost FROM wiki',
1, 5, false);
seq | path_seq | start_vid | end_vid | node | edge | cost | agg_cost
-----+----------+-----------+---------+------+------+------+----------
1 | 1 | 1 | 5 | 1 | 2 | 9 | 0
2 | 2 | 1 | 5 | 3 | 6 | 2 | 9
3 | 3 | 1 | 5 | 6 | 9 | 9 | 11
4 | 4 | 1 | 5 | 5 | -1 | 0 | 20
(4 rows)
Para ir de
![graph G {
rankdir="LR";
1 [color="red"];
5 [color="green"];
1 -- 2 [label="(7)"];
5 -- 6 [label="(9)", color="blue"];
1 -- 3 [label="(9)", color="blue"];
1 -- 6 [label="(14)"];
2 -- 3 [label="(10)"];
2 -- 4 [label="(13)"];
3 -- 4 [label="(11)"];
3 -- 6 [label="(2)", color="blue"];
4 -- 5 [label="(6)"];
}](_images/graphviz-fdf01cf24599e17f1d95f59e619139a55bdedbb0.png)
Información de vertices¶
Para obtener la información de los vértices, use pgr_extractVertices – Propuesto
SELECT id, in_edges, out_edges
FROM pgr_extractVertices('SELECT id, source, target FROM wiki');
id | in_edges | out_edges
----+----------+-----------
3 | {2,4} | {6,7}
5 | {8} | {9}
4 | {5,7} | {8}
2 | {1} | {4,5}
1 | | {1,2,3}
6 | {3,6,9} |
(6 rows)
Grafos con geometrías¶
Crear una Base de Datos de Ruteo¶
El primer paso para crear una base de datos y cargar pgRouting en la base de datos.
Típicamente se crea una base de datos para cada proyecto.
Una vez que se tenga una base de datos, cargue sus datos y construya la aplicación de routeo en esa base de datos.
createdb sampledata
psql sampledata -c "CREATE EXTENSION pgrouting CASCADE"
Cargar Datos¶
Hay varias maneras de cargar tus datos en pgRouting.
Creando manualmente la base de datos.
Datos Muestra: un pequeño grafo utilizado en los ejemplos de la documentación
Usando osm2pgrouting
Existen varias herramientas de codigo abierto que pueden ayudar, como:
- shp2pgsql:
cargador a postgresql de archivos shape
- ogr2ogr:
herramienta de conversión de datos vectoriales
- osm2pgsql:
cargar datos de OSM a postgresql
Tener en cuenta que estas herramientas no importan los datos a una estructura compatible con pgRouting y cuando esto sucede, la topología necesita ser ajustada.
Rompe en segmentos cada intersección segmento-segmento
Cuando falte, agregue columnas y asigne valores a
source,target,cost,reverse_cost.Conecte un grafo desconectado.
Crea la topología de un grafo completo
Crea uno o mas grafos según la aplicación que se desarrolla.
Crea un grafo contraído para calles de alta velocidad
Crear grafos por estado/país
En pocas palabras:
Prepara el grafo
Qué y cómo preparar el grafo, dependerá de la aplicación y/o de la calidad de los datos y/o de lo cerca que esté la información de tener una topología utilizable por pgRouting y/o algunos otros factores no mencionados.
Los pasos para preparar el grafo implican operaciones de geometría utilizando PostGIS y algunos otros implican operaciones de grafos como pgr_contraction para contraer un grafo.
El taller tiene un paso a paso sobre cómo preparar un grafo utilizando datos de Open Street Map, para una pequeña aplicación.
El uso de índices en el diseño de bases de datos en general:
Tener las geometrías indexadas.
Tener indexadas las columnas de identificadores.
Consultar la documentación de PostgreSQL y la documentación de PostGIS.
Construir una topología de ruteo¶
La información básica para usar la mayoría de las funciones de pgRouting id, source, target, cost, [reverse_cost] es lo que en pgRouting se llama topología de ruteo.
reverse_cost es opcional pero se recomienda encarecidamente tenerlo para reducir el tamaño de la base de datos debido al tamaño de las columnas de geometría. Dicho esto, en esta documentación se utiliza reverse_cost.
Cuando los datos vienen con geometrías y no hay topología de ruteo, entonces este paso es necesario.
Todos los vértices iniciales y finales de las geometrías necesitan un identificador que se almacenará en las columnas source y target de la tabla de los datos. Del mismo modo, cost y reverse_cost necesitan tener el valor de atravesar la arista en ambas direcciones.
Si las columnas no existen, hay que añadirlas a la tabla en cuestión. (véase ALTER TABLE)
La función pgr_extractVertices – Propuesto se utiliza para crear una tabla de vértices basada en el identificador de arista y la geometría de la arista del grafo.
Finalmente, utilizando los datos almacenados en las tablas de vértices, se rellenan los campos source y target.
Consulte Datos Muestra para ver un ejemplo de construcción de una topología.
Los datos procedentes de OSM y utilizando osm2pgrouting <https://github.com/pgRouting/osm2pgrouting>`__ como herramienta de importación, vienen con la topología de ruteo. Ver un ejemplo de uso de ``osm2pgrouting en el workshop.
Ajustar los costes¶
Para este ejemplo los valores coste y coste_inverso van a ser el doble de la longitud de la geometría.
Actualizar los costes a la longitud de la geometría¶
Suponer que las columnas cost y reverse_cost de los datos de la muestra representan:
Utilizando esa información de actualización a la longitud de las geometrías:
UPDATE edges SET
cost = sign(cost) * ST_length(geom) * 2,
reverse_cost = sign(reverse_cost) * ST_length(geom) * 2;
UPDATE 18
Lo que da los siguientes resultados:
SELECT id, cost, reverse_cost FROM edges;
id | cost | reverse_cost
----+--------------------+--------------------
6 | 2 | 2
7 | 2 | 2
4 | 2 | 2
5 | 2 | -2
8 | 2 | 2
12 | 2 | -2
11 | 2 | -2
10 | 2 | 2
17 | 2.999999999998 | 2.999999999998
14 | 2 | 2
18 | 3.4000000000000004 | 3.4000000000000004
13 | 2 | -2
15 | 2 | 2
16 | 2 | 2
9 | 2 | 2
3 | -2 | 2
1 | 2 | 2
2 | -2 | 2
(18 rows)
Tener en cuenta que para poder seguir los ejemplos de la documentación, todo se basa en el grafo original.
Volviendo a los datos originales:
UPDATE edges SET
cost = sign(cost),
reverse_cost = sign(reverse_cost);
UPDATE 18
Actualizar los costes en función de los códigos¶
Otros conjuntos de datos, pueden tener una columna con valores como
FTflujo de vehículos en la dirección de la geometríaTFflujo del vehículo opuesto a la dirección de la geometríaBflujo de vehículos en ambas direcciones
Preparar una columna de códigos para el ejemplo:
ALTER TABLE edges ADD COLUMN direction TEXT;
ALTER TABLE
UPDATE edges SET
direction = CASE WHEN (cost>0 AND reverse_cost>0) THEN 'B' /* both ways */
WHEN (cost>0 AND reverse_cost<0) THEN 'FT' /* direction of the LINESSTRING */
WHEN (cost<0 AND reverse_cost>0) THEN 'TF' /* reverse direction of the LINESTRING */
ELSE '' END;
UPDATE 18
/* unknown */
Ajuste de los costes en función de los códigos:
UPDATE edges SET
cost = CASE WHEN (direction = 'B' OR direction = 'FT')
THEN ST_length(geom) * 2
ELSE -1 END,
reverse_cost = CASE WHEN (direction = 'B' OR direction = 'TF')
THEN ST_length(geom) * 2
ELSE -1 END;
UPDATE 18
Lo que da los siguientes resultados:
SELECT id, cost, reverse_cost FROM edges;
id | cost | reverse_cost
----+--------------------+--------------------
6 | 2 | 2
7 | 2 | 2
4 | 2 | 2
5 | 2 | -1
8 | 2 | 2
12 | 2 | -1
11 | 2 | -1
10 | 2 | 2
17 | 2.999999999998 | 2.999999999998
14 | 2 | 2
18 | 3.4000000000000004 | 3.4000000000000004
13 | 2 | -1
15 | 2 | 2
16 | 2 | 2
9 | 2 | 2
3 | -1 | 2
1 | 2 | 2
2 | -1 | 2
(18 rows)
Volviendo a los datos originales:
UPDATE edges SET
cost = sign(cost),
reverse_cost = sign(reverse_cost);
UPDATE 18
ALTER TABLE edges DROP COLUMN direction;
ALTER TABLE
Compruebe la Topología de Ruteo¶
Hay muchos problemas posibles en un grafo.
Es posible que los datos utilizados no se hayan diseñado teniendo en cuenta el ruteo.
Un grafo tiene unos requisitos muy específicos.
El grafo está desconectado.
Hay intersecciones no deseadas.
El grafo es demasiado grande y hay que contraerlo.
Se necesita un subgrafo para la aplicación.
y muchos otros problemas que el usuario de pgRouting, es decir, el desarrollador de aplicaciones, puede encontrar.
Aristas que se cruzan¶
Para obtener las aristas que se cruzan:
SELECT a.id, b.id
FROM edges AS a, edges AS b
WHERE a.id < b.id AND st_crosses(a.geom, b.geom);
id | id
----+----
13 | 18
(1 row)
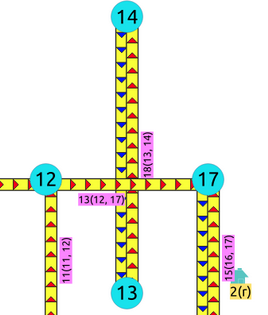
Esa información es correcta, por ejemplo, cuando en términos de vehículos, es un túnel o puente cruczando sobre otra carretera.
Puede ser incorrecto, por ejemplo:
Cuando en realidad es una intersección de carreteras, donde los vehículos pueden hacer giros.
En cuanto a las líneas eléctricas, son capaces de cambiar de carretera incluso en un túnel o puente.
Cuando es incorrecta, hay que arreglarla:
Para vehículos y peatones
Si los datos provienen de OSM y fueron importados a la base de datos utilizando
osm2pgrouting, la corrección debe hacerse en el OSM portal y los datos ser importados de nuevo.En general, cuando los datos proceden de un proveedor que tiene los datos preparados para el ruteo de vehículos, y hay un problema, los datos deben ser fijados por el proveedor
Para aplicaciones muy específicas
Los datos son correctos desde el punto de vista de la circulación de vehículos o peatones.
Los datos necesitan un arreglo local para la aplicación específica.
Una vez analizados uno a uno los cruces, para los que necesitan un arreglo local, hay que dividir las aristas.
SELECT ST_AsText((ST_Dump(ST_Split(a.geom, b.geom))).geom)
FROM edges AS a, edges AS b
WHERE a.id = 13 AND b.id = 18
UNION
SELECT ST_AsText((ST_Dump(ST_Split(b.geom, a.geom))).geom)
FROM edges AS a, edges AS b
WHERE a.id = 13 AND b.id = 18;
st_astext
---------------------------
LINESTRING(3.5 2.3,3.5 3)
LINESTRING(3 3,3.5 3)
LINESTRING(3.5 3,4 3)
LINESTRING(3.5 3,3.5 4)
(4 rows)
Hay que añadir las nuevas aristas a la tabla de aristas, actualizar el resto de atributos en las nuevas aristas, eliminar las aristas antiguas y actualizar la topología de encaminamiento.
Añadir aristas divididas¶
Para cada par de aristas de cruce debe realizarse un proceso similar a éste.
Las columnas insertadas y la forma en que se calculan se basan en la aplicación. Por ejemplo, si las aristas tienen un rasgo nombre, se copiará esa columna.
Para llos cálculos de pgRouting
Se puede utilizar un factor basado en la posición de la intersección de las aristas para ajustar las columnas
costyreverse_cost.La información de capacidad, utilizada en las funciones Flow - Familia de funciones no necesita cambiar al dividir aristas.
WITH
first_edge AS (
SELECT (ST_Dump(ST_Split(a.geom, b.geom))).path[1],
(ST_Dump(ST_Split(a.geom, b.geom))).geom,
ST_LineLocatePoint(a.geom,ST_Intersection(a.geom,b.geom)) AS factor
FROM edges AS a, edges AS b
WHERE a.id = 13 AND b.id = 18),
first_segments AS (
SELECT path, first_edge.geom,
capacity, reverse_capacity,
CASE WHEN path=1 THEN factor * cost
ELSE (1 - factor) * cost END AS cost,
CASE WHEN path=1 THEN factor * reverse_cost
ELSE (1 - factor) * reverse_cost END AS reverse_cost
FROM first_edge , edges WHERE id = 13),
second_edge AS (
SELECT (ST_Dump(ST_Split(b.geom, a.geom))).path[1],
(ST_Dump(ST_Split(b.geom, a.geom))).geom,
ST_LineLocatePoint(b.geom,ST_Intersection(a.geom,b.geom)) AS factor
FROM edges AS a, edges AS b
WHERE a.id = 13 AND b.id = 18),
second_segments AS (
SELECT path, second_edge.geom,
capacity, reverse_capacity,
CASE WHEN path=1 THEN factor * cost
ELSE (1 - factor) * cost END AS cost,
CASE WHEN path=1 THEN factor * reverse_cost
ELSE (1 - factor) * reverse_cost END AS reverse_cost
FROM second_edge , edges WHERE id = 18),
all_segments AS (
SELECT * FROM first_segments
UNION
SELECT * FROM second_segments)
INSERT INTO edges
(capacity, reverse_capacity,
cost, reverse_cost,
x1, y1, x2, y2,
geom)
(SELECT capacity, reverse_capacity, cost, reverse_cost,
ST_X(ST_StartPoint(geom)), ST_Y(ST_StartPoint(geom)),
ST_X(ST_EndPoint(geom)), ST_Y(ST_EndPoint(geom)),
geom
FROM all_segments);
INSERT 0 4
Añadiendo nuevos vértices¶
Después de añadir todas las aristas de división requeridas por la aplicación, es necesario añadir los vértices recién creados a la tabla de vértices.
INSERT INTO vertices (in_edges, out_edges, x, y, geom)
(SELECT nv.in_edges, nv.out_edges, nv.x, nv.y, nv.geom
FROM pgr_extractVertices('SELECT id, geom FROM edges') AS nv
LEFT JOIN vertices AS v USING(geom) WHERE v.geom IS NULL);
INSERT 0 1
Actualizar la topología de aristas¶
/* -- set the source information */
UPDATE edges AS e
SET source = v.id
FROM vertices AS v
WHERE source IS NULL AND ST_StartPoint(e.geom) = v.geom;
UPDATE 4
/* -- set the target information */
UPDATE edges AS e
SET target = v.id
FROM vertices AS v
WHERE target IS NULL AND ST_EndPoint(e.geom) = v.geom;
UPDATE 4
Eliminar las aristas sobrantes¶
Una vez que toda la información significativa que necesita la aplicación se ha transportado a las nuevas aristas, se pueden eliminar las aristas de cruce.
DELETE FROM edges WHERE id IN (13, 18);
DELETE 2
Existen otras opciones para realizar esta tarea, como crear una vista, o una vista materializada.
Actializar la topología de vértices¶
Para mantener la coherencia del grafo, es necesario actualizar la topología de los vértices
UPDATE vertices AS v SET
in_edges = nv.in_edges, out_edges = nv.out_edges
FROM (SELECT * FROM pgr_extractVertices('SELECT id, geom FROM edges')) AS nv
WHERE v.geom = nv.geom;
UPDATE 18
Comprobación del cruce de aristas¶
No hay aristas que se crucen en el grafo.
SELECT a.id, b.id
FROM edges AS a, edges AS b
WHERE a.id < b.id AND st_crosses(a.geom, b.geom);
id | id
----+----
(0 rows)
Grafos desconectados¶
Para obtener la conectividad del grafo:
SELECT * FROM pgr_connectedComponents(
'SELECT id, source, target, cost, reverse_cost FROM edges'
);
seq | component | node
-----+-----------+------
1 | 1 | 1
2 | 1 | 3
3 | 1 | 5
4 | 1 | 6
5 | 1 | 7
6 | 1 | 8
7 | 1 | 9
8 | 1 | 10
9 | 1 | 11
10 | 1 | 12
11 | 1 | 13
12 | 1 | 14
13 | 1 | 15
14 | 1 | 16
15 | 1 | 17
16 | 1 | 18
17 | 2 | 2
18 | 2 | 4
(18 rows)
En este ejemplo, el componente
Este grafo debe estar conectado.
Nota
Con el grafo original de esta documentación, habría 3 componentes, ya que la arista de cruce en este grafo es un componente diferente.
Preparar el almacenamiento de la información de conexión¶
ALTER TABLE vertices ADD COLUMN component BIGINT;
ALTER TABLE
ALTER TABLE edges ADD COLUMN component BIGINT;
ALTER TABLE
Guardar la información de conexión de los vértices¶
UPDATE vertices SET component = c.component
FROM (SELECT * FROM pgr_connectedComponents(
'SELECT id, source, target, cost, reverse_cost FROM edges'
)) AS c
WHERE id = node;
UPDATE 18
Guardar la información de conexión de las aristas¶
UPDATE edges SET component = v.component
FROM (SELECT id, component FROM vertices) AS v
WHERE source = v.id;
UPDATE 20
Obtener el vértice más cercano¶
Usando pgr_findCloseEdges el vértice más cercano al componente
SELECT edge_id, fraction, ST_AsText(edge) AS edge, id AS closest_vertex
FROM pgr_findCloseEdges(
$$SELECT id, geom FROM edges WHERE component = 1$$,
(SELECT array_agg(geom) FROM vertices WHERE component = 2),
2, partial => false) JOIN vertices USING (geom) ORDER BY distance LIMIT 1;
edge_id | fraction | edge | closest_vertex
---------+----------+--------------------------------------+----------------
14 | 0.5 | LINESTRING(1.999999999999 3.5,2 3.5) | 4
(1 row)
La arista edge se puede utilizar para conectar los componentes, utilizando la información fraction sobre la arista
Conectando componentes¶
Existen tres formas básicas de conectar los componentes
Del vértice al punto inicial de la arista
Desde el vértice hasta el punto final de la arista
Del vértice al vértice más cercano de la arista
Esta solución requiere dividir el borde.
La siguiente consulta muestra las tres formas de conectar los componentes:
WITH
info AS (
SELECT
edge_id, fraction, side, distance, ce.geom, edge, v.id AS closest,
source, target, capacity, reverse_capacity, e.geom AS e_geom
FROM pgr_findCloseEdges(
$$SELECT id, geom FROM edges WHERE component = 1$$,
(SELECT array_agg(geom) FROM vertices WHERE component = 2),
2, partial => false) AS ce
JOIN vertices AS v USING (geom)
JOIN edges AS e ON (edge_id = e.id)
ORDER BY distance LIMIT 1),
three_options AS (
SELECT
closest AS source, target, 0 AS cost, 0 AS reverse_cost,
capacity, reverse_capacity,
ST_X(geom) AS x1, ST_Y(geom) AS y1,
ST_X(ST_EndPoint(e_geom)) AS x2, ST_Y(ST_EndPoint(e_geom)) AS y2,
ST_MakeLine(geom, ST_EndPoint(e_geom)) AS geom
FROM info
UNION
SELECT closest, source, 0, 0, capacity, reverse_capacity,
ST_X(geom) AS x1, ST_Y(geom) AS y1,
ST_X(ST_StartPoint(e_geom)) AS x2, ST_Y(ST_StartPoint(e_geom)) AS y2,
ST_MakeLine(info.geom, ST_StartPoint(e_geom))
FROM info
/*
UNION
-- This option requires splitting the edge
SELECT closest, NULL, 0, 0, capacity, reverse_capacity,
ST_X(geom) AS x1, ST_Y(geom) AS y1,
ST_X(ST_EndPoint(edge)) AS x2, ST_Y(ST_EndPoint(edge)) AS y2,
edge
FROM info */
)
INSERT INTO edges
(source, target,
cost, reverse_cost,
capacity, reverse_capacity,
x1, y1, x2, y2,
geom)
(SELECT
source, target, cost, reverse_cost, capacity, reverse_capacity,
x1, y1, x2, y2, geom
FROM three_options);
INSERT 0 2
Revisando componentes¶
Ignorando la arista que requiere más trabajo. El grafo está ahora totalmente conectado, ya que sólo hay un componente.
SELECT * FROM pgr_connectedComponents(
'SELECT id, source, target, cost, reverse_cost FROM edges'
);
seq | component | node
-----+-----------+------
1 | 1 | 1
2 | 1 | 2
3 | 1 | 3
4 | 1 | 4
5 | 1 | 5
6 | 1 | 6
7 | 1 | 7
8 | 1 | 8
9 | 1 | 9
10 | 1 | 10
11 | 1 | 11
12 | 1 | 12
13 | 1 | 13
14 | 1 | 14
15 | 1 | 15
16 | 1 | 16
17 | 1 | 17
18 | 1 | 18
(18 rows)
Contracción de un grafo¶
El grafo puede reducirse de tamaño utilizando Contraction - Familia de funciones
El cuando contraer dependerá del tamaño del gráfico, de los tiempos de procesamiento, de la corrección de los datos, de la aplicación final o de cualquier otro factor no mencionado.
Un método bastante bueno para saber si la contracción puede ser útil es por el número de callejones sin salida y/o el número de aristas lineales.
En Contraction - Familia de funciones se describe un método completo sobre cómo contraer y cómo utilizar el grafo contraído
Callejones sin salida¶
Para obtener los callejones sin salida:
SELECT id FROM vertices
WHERE array_length(in_edges || out_edges, 1) = 1;
id
----
1
5
9
13
14
2
4
(7 rows)
Esa información es correcta, por ejemplo, cuando el punto muerto está en el límite del gráfico importado.
Visualmente el nodo
¿Es correcto?
Hay un bordillo tan pequeño:
¿Eso no permite a un vehículo utilizar esa intersección visual?
¿Es la aplicación para peatones y por lo tanto el peatón puede caminar fácilmente en una acera pequeña?
¿Es la aplicación para la electricidad y las líneas eléctricas que se puede extender fácilmente en la parte superior de la acera pequeña?
¿Hay un gran acantilado y desde la vista de las águilas parece que el callejón sin salida está cerca del segmento?
Cuando hay muchos callejones sin salida, para acelerar, se pueden utilizar las funciones de Contraction - Familia de funciones para dividir el problema.
Bordes lineales¶
Para obtener las aristas lineales:
SELECT id FROM vertices
WHERE array_length(in_edges || out_edges, 1) = 2;
id
----
3
15
17
(3 rows)
Esta información es correcta, por ejemplo, cuando la aplicación tiene en cuenta los topes o las señales de stop.
Cuando hay muchas aristas lineales, para acelerar, se pueden utilizar las funciones Contraction - Familia de funciones para dividir el problema.
Estructura de la función¶
Una vez realizado el trabajo de preparación del grafo anterior, es el momento de utilizar un
La forma general de una llamada a una función de pgRouting es:
pgr_<nombre>(Consultas internas, parámetros, [
Parámetros opcionales)
Donde:
Consultas internas: Son parámetros obligatorios que son
TEXTque contienen consultas SQL.Parámetros: Parámetros obligatorios adicionales que necesita la función.
Parámetros opcionales: Son parámetros nombrados no obligatorios que tienen un valor por defecto cuando se omiten.
Los parámetros obligatorios son parámetros de posición, los parámetros opcionales son parámetros nombrados.
Por ejemplo, para esta firma pgr_dijkstra:
pgr_dijkstra(SQL de aristas, salidas, destinos, [directed])
-
Es el primer parámetro.
Es obligatorio.
Es una consulta interna.
No tiene nombre, por lo que SQL de aristas da una idea del tipo de consulta interna que hay que utilizar
vid inical:
Es el segundo parámetro.
Es obligatorio.
No tiene nombre, por lo que salida da una idea de lo que debe contener el valor del segundo parámetro.
destino
Es el tercer parámetro.
Es obligatorio.
No tiene nombre, por lo que destino da una idea de lo que debe contener el valor del tercer parámetro
directedEs el cuarto parámetro.
Es opcional.
Tiene un nombre.
La descripción completa de los parámetros se encuentra en la sección Parámetros de cada función.
Sobrecargas de funciones¶
Una función puede tener diferentes sobrecargas. Las más comunes se llaman:
Dependiendo de la sobrecarga, los tipos de los parámetros cambian.
Uno: CUALQUIER-ENTERO
Muchos:
ARRAY[CUALQUIER-ENTERO]
Dependiendo de la función, las sobrecargas pueden variar. Pero el concepto de cambio de tipo de parámetro sigue siendo el mismo.
Uno a Uno¶
Cuando se rutea desde:
Desde un vértice inicial
al un vértice final
Uno a Muchos¶
Cuando se rutea desde:
Desde un vértice inicial
a los vértices finales many
Muchos a Uno¶
Cuando se rutea desde:
Desde muchos vértices iniciales
al un vértice final
Muchos a Muchos¶
Cuando se rutea desde:
Desde muchos vértices iniciales
a los vértices finales many
Combinaciones¶
Cuando se rutea desde:
A partir de muchos diferentes vértices de inicio
a muchos diferentes vértices finales
Cada tupla especifica un par de vértices iniciales y un vértice final
Los usuarios pueden definir las combinaciones como deseen.
Necesita una SQL de combinaciones
Consultas Internas¶
Existen varios tipos de consultas internas válidas y también las columnas devueltas dependen de la función. El tipo de consulta interna dependerá de los requisitos de la función. Para simplificar la variedad de tipos, se utiliza ANY-INTEGER y ANY-NUMERICAL.
Donde:
- ENTEROS:
SMALLINT, INTEGER, BIGINT- FLOTANTES:
SMALLINT, INTEGER, BIGINT, REAL, FLOAT
SQL aristas¶
General¶
SQL de aristas para
Algunas funciones no categorizadas
Columna |
Tipo |
x Defecto |
Descripción |
|---|---|---|---|
|
ENTEROS |
Identificador de la arista. |
|
|
ENTEROS |
Identificador del primer vértice de la arista. |
|
|
ENTEROS |
Identificador del segundo vértice de la arista. |
|
|
FLOTANTES |
Peso de la arista ( |
|
|
FLOTANTES |
-1 |
Peso de la arista (
|
Donde:
- ENTEROS:
SMALLINT,INTEGER,BIGINT- FLOTANTES:
SMALLINT,INTEGER,BIGINT,REAL,FLOAT
General sin id¶
SQL de aristas para
Columna |
Tipo |
x Defecto |
Descripción |
|---|---|---|---|
|
ENTEROS |
Identificador del primer vértice de la arista. |
|
|
ENTEROS |
Identificador del segundo vértice de la arista. |
|
|
FLOTANTES |
Peso de la arista ( |
|
|
FLOTANTES |
-1 |
Peso de la arista (
|
Donde:
- ENTEROS:
SMALLINT,INTEGER,BIGINT- FLOTANTES:
SMALLINT,INTEGER,BIGINT,REAL,FLOAT
General con (X,Y)¶
SQL de aristas para
Parámetro |
Tipo |
x Defecto |
Descripción |
|---|---|---|---|
|
ENTEROS |
Identificador de la arista. |
|
|
ENTEROS |
Identificador del primer vértice de la arista. |
|
|
ENTEROS |
Identificador del segundo vértice de la arista. |
|
|
FLOTANTES |
Peso de la arista (
|
|
|
FLOTANTES |
-1 |
Peso de la arista (
|
|
FLOTANTES |
Coordenada X del vértice |
|
|
FLOTANTES |
Coordenada Y del vértice |
|
|
FLOTANTES |
Coordenada X del vértice |
|
|
FLOTANTES |
Coordenada Y del vértice |
Donde:
- ENTEROS:
SMALLINT,INTEGER,BIGINT- FLOTANTES:
SMALLINT,INTEGER,BIGINT,REAL,FLOAT
Flujo¶
SQL de aristas para Flow - Familia de funciones
SQL de aristas para
Columna |
Tipo |
x Defecto |
Descripción |
|---|---|---|---|
|
ENTEROS |
Identificador de la arista. |
|
|
ENTEROS |
Identificador del primer vértice de la arista. |
|
|
ENTEROS |
Identificador del segundo vértice de la arista. |
|
|
ENTEROS |
Peso de la arista ( |
|
|
ENTEROS |
-1 |
Peso de la arista (
|
Donde:
- ENTEROS:
SMALLINT,INTEGER,BIGINT- FLOTANTES:
SMALLINT,INTEGER,BIGINT,REAL,FLOAT
SQL de aristas para las siguientes funciones de Flow - Familia de funciones
Columna |
Tipo |
x Defecto |
Descripción |
|---|---|---|---|
|
ENTEROS |
Identificador de la arista. |
|
|
ENTEROS |
Identificador del primer vértice de la arista. |
|
|
ENTEROS |
Identificador del segundo vértice de la arista. |
|
|
ENTEROS |
Capacidad de la arista (
|
|
|
ENTEROS |
-1 |
Capacidad de la arista (
|
|
FLOTANTES |
Peso de la arista ( |
|
|
FLOTANTES |
Peso de la arista ( |
Donde:
- ENTEROS:
SMALLINT,INTEGER,BIGINT- FLOTANTES:
SMALLINT,INTEGER,BIGINT,REAL,FLOAT
SQL Combinaciones¶
Utilizado en combinación firmas
Parámetro |
Tipo |
Descripción |
|---|---|---|
|
ENTEROS |
Identificador del vértice de partida. |
|
ENTEROS |
Identificador del vértice de llegada. |
Donde:
- ENTEROS:
SMALLINT,INTEGER,BIGINT
SQL restricciones¶
Columna |
Tipo |
Descripción |
|---|---|---|
|
|
Secuencia de identificadores de aristas que forman un camino que no se permite tomar. - Arreglos vacios o |
|
FLOTANTES |
Costo de tomar el camino prohibido. |
Donde:
- ENTEROS:
SMALLINT,INTEGER,BIGINT- FLOTANTES:
SMALLINT,INTEGER,BIGINT,REAL,FLOAT
SQL de puntos¶
SQL de puntos para
Parámetro |
Tipo |
x Defecto |
Descripción |
|---|---|---|---|
|
ENTEROS |
valor |
Identificador del punto.
|
|
ENTEROS |
Identificador de la arista «más cercana» al punto. |
|
|
FLOTANTES |
El valor en <0,1> que indica la posición relativa desde el primer punto de la arista. |
|
|
|
|
Valor en [
|
Donde:
- ENTEROS:
SMALLINT,INTEGER,BIGINT- FLOTANTES:
SMALLINT,INTEGER,BIGINT,REAL,FLOAT
Parámetros¶
El parámetro principal de la mayoría de las funciones pgRouting es una consulta que selecciona las aristas del grafo.
Parámetro |
Tipo |
Descripción |
|---|---|---|
|
SQL de aristas descritas más adelante. |
Dependiendo de la familia o categoría de una función tendrá parámetros adicionales, algunos de ellos son obligatorios y otros opcionales.
Los parámetros obligatorios no tienen nombre y deben indicarse en el orden requerido. Los parámetros opcionales son parámetros con nombre y tendrán un valor por defecto.
Párametros para las funciones Via¶
Parámetro |
Tipo |
x Defecto |
Descripción |
|---|---|---|---|
|
Consulta SQL como se describe. |
||
vértices |
|
Arreglo ordenado de identificadores de vértices que serán visitados. |
|
|
|
|
|
|
|
|
|
|
|
|
|
Para las funciones de TRSP¶
Columna |
Tipo |
Descripción |
|---|---|---|
|
Consulta SQL como se describe. |
|
|
Consulta SQL como se describe. |
|
|
SQL de combinaciones como se describe a abajo |
|
salida |
ENTEROS |
Identificador del vértice de partida. |
salidas |
|
Arreglo de identificadores de vértices destino. |
destino |
ENTEROS |
Identificador del vértice de partida. |
destinos |
|
Arreglo de identificadores de vértices destino. |
Donde:
- ENTEROS:
SMALLINT,INTEGER,BIGINT
Columnas de resultados¶
Hay varios tipos de columnas devueltas que dependen de la función.
Columnas de resultados para una ruta¶
Se utiliza en funciones que devuelven una solución de ruta
Devuelve el conjunto de (seq, path_seq [, start_vid] [, end_vid], node, edge, cost, agg_cost)
Columna |
Tipo |
Descripción |
|---|---|---|
|
|
Valor secuencial a partir de 1. |
|
|
Posición relativa en la ruta. Tiene el valor 1 para el inicio de una ruta. |
|
|
Identificador del vértice inicial. Se devuelve cuando hay varias vetrices iniciales en la consulta. |
|
|
Identificador del vértice final. Se devuelve cuando hay varios vértices finales en la consulta. |
|
|
Identificador del nodo en la ruta de |
|
|
Identificador de la arista utilizado para ir del |
|
|
Costo para atravesar desde |
|
|
Costo agregado desde |
Se utiliza en las funciones siguientes:
Devuelve el conjunto de (seq, path_seq [, start_pid] [, end_pid], node, edge, cost, agg_cost)
Columna |
Tipo |
Descripción |
|---|---|---|
|
|
Valor secuencial a partir de 1. |
|
|
Posición relativa en la ruta.
|
|
|
Identificador del vértice/punto inicial de la ruta.
|
|
|
Identificador d vértice/punto final del camino.
|
|
|
Identificador del nodo en la ruta de
|
|
|
Identificador de la arsita utilizada para ir del
|
|
|
Costo para atravesar desde
|
|
|
Costo agregado desde
|
Se utiliza en las funciones siguientes:
Regresa (seq, path_seq, start_vid, end_vid, node, edge, cost, agg_cost)
Columna |
Tipo |
Descripción |
|---|---|---|
|
|
Valor secuencial a partir de 1. |
|
|
Posición relativa en la ruta. Tiene el valor 1 para el inicio de una ruta. |
|
|
Identificador del vértice inicial de la ruta actual. |
|
|
Identificador del vértice final de la ruta actual. |
|
|
Identificador del nodo en la ruta de |
|
|
Identificador de la arista utilizado para ir del |
|
|
Costo para atravesar desde |
|
|
Costo agregado desde |
Varias rutas¶
Selectivo para múltiples rutas.¶
Las columnas dependen de la llamada a la función.
Conjunto de (seq, path_id, path_seq [, start_vid] [, end_vid], node, edge, cost, agg_cost)
Columna |
Tipo |
Descripción |
|---|---|---|
|
|
Valor secuencial a partir de 1. |
|
|
Identificador del camino.
|
|
|
Posición relativa en la ruta. Tiene el valor 1 para el inicio de una ruta. |
|
|
Identificador del vértice inicial. Se devuelve cuando hay varias vetrices iniciales en la consulta. |
|
|
Identificador del vértice final. Se devuelve cuando hay varios vértices finales en la consulta. |
|
|
Identificador del nodo en la ruta de |
|
|
Identificador de la arista utilizado para ir del |
|
|
Costo para atravesar desde |
|
|
Costo agregado desde |
No selectivo para rutas múltiples¶
Independientemente de la llamada, se devuelven todas las columnas.
Devuelve el conjunto de (seq, path_id, path_seq, start_vid, end_vid, node, edge, cost, agg_cost)
Columna |
Tipo |
Descripción |
|---|---|---|
|
|
Valor secuencial a partir de 1. |
|
|
Identificador del camino.
|
|
|
Posición relativa en la ruta. Tiene el valor 1 para el inicio de una ruta. |
|
|
Identificador del vértice de salida. |
|
|
Identificador del vértice final. |
|
|
Identificador del nodo en la ruta de |
|
|
Identificador de la arista utilizado para ir del |
|
|
Costo para atravesar desde |
|
|
Costo agregado desde |
Columnas de resultados de las funciones de costes¶
Se utiliza en
Conjunto de (start_vid, end_vid, agg_cost)
Columna |
Tipo |
Descripción |
|---|---|---|
|
|
Identificador del vértice de salida. |
|
|
Identificador del vértice final. |
|
|
Costo afregado desde |
Nota
Cuando las columnas del vértice inicial o del destino continen valores negativos, el identificador es para un Punto.
Columnas de resultados para funciones de flujo¶
SQL de aristas para lo siguiente
Columna |
Tipo |
Descripción |
|---|---|---|
seq |
|
Valor secuencial a partir de 1. |
arista |
|
Identificador de la arista en la consulta original(edges_sql). |
start_vid |
|
Identificador del primer vértice de la arista. |
end_vid |
|
Identificador del segundo vértice de la arista. |
flujo |
|
Flujo a través del arista en la dirección ( |
residual_capacity |
|
Capacidad residual del arista en la dirección ( |
SQL de aristas para las siguientes funciones de Flow - Familia de funciones
Columna |
Tipo |
Descripción |
|---|---|---|
seq |
|
Valor secuencial a partir de 1. |
arista |
|
Identificador de la arista en la consulta original(edges_sql). |
origen |
|
Identificador del primer vértice de la arista. |
objetivo |
|
Identificador del segundo vértice de la arista. |
flujo |
|
Flujo a través de la arista en la dirección (origen, destino). |
residual_capacity |
|
Capacidad residual de la arista en la dirección (origen, destino). |
costo |
|
El costo de enviar este flujo a través de la arista en la dirección (origen, destino). |
agg_cost |
|
El costo agregado. |
Columnas de resultados para funciones de árbol de expansión¶
SQL de aristas para lo siguiente
Regresa el conjunto de (edge, cost)
Columna |
Tipo |
Descripción |
|---|---|---|
|
|
Identificador de la arista. |
|
|
Coste para atravezar el borde. |
Consejos de Rendimiento¶
Para las funciones de Ruteo¶
Para obtener resultados más rápidos, delimitar las consultas a un área de interés para el ruteo.
En este ejemplo, usar una consulta SQL interna que no incluya algunas aristas en la función de ruteo y dentro del área de los resultados.
SELECT * FROM pgr_dijkstra($$
SELECT id, source, target, cost, reverse_cost from edges
WHERE geom && (SELECT st_buffer(geom, 1) AS myarea
FROM edges WHERE id = 2)$$,
1, 2);
seq | path_seq | start_vid | end_vid | node | edge | cost | agg_cost
-----+----------+-----------+---------+------+------+------+----------
(0 rows)
Cómo contribuir¶
Wiki
Edita una página existente Wiki de pgRouting.
O crea una nueva página Wiki
Crear una página en el Wiki de pgRouting
Asigne al título un nombre apropiado
Agregar funcionalidad a pgRouting
Consultar la documentation de desarrolladores
Índices y tablas